Prompt Engineering Is System Design: Moving from Chat to Structured Workflows
Large Language Models are powerful, but they are highly sensitive to how instructions are written. Even small changes in wording can produce vastly different outputs. In real-world implementations, this variability creates inconsistency, errors, and integration challenges.
Over time, we realized that effective prompting is not about asking better questions. It is about designing structured instructions that guide the model clearly and predictably. In this post, we share our approach to prompt structuring, how we implemented it in real workflows, and the business impact it drives.
Prompt Engineering Is System Design
A prompt is not just a question. It is:
A set of instructions
A definition of constraints
A formatting guide
A behavioral boundary for the model
When prompts are written casually, outputs vary wildly. The same task can produce different styles, extra explanations, or wrong assumptions. Language models generate responses based on learned probability patterns. When instructions are vague, the range of possible responses is wide. Clear structure and constraints narrow that range, making outputs predictable.
That is why we see prompt engineering as system design. It is about giving the model clear direction, defined boundaries, and structured expectations.
🧠 From Casual Chat to Structured Intelligence
The shift from casual prompting to structured system design is not philosophical — it is architectural. The visual below captures the difference between ad-hoc prompts and layered, production-ready LLM workflows.
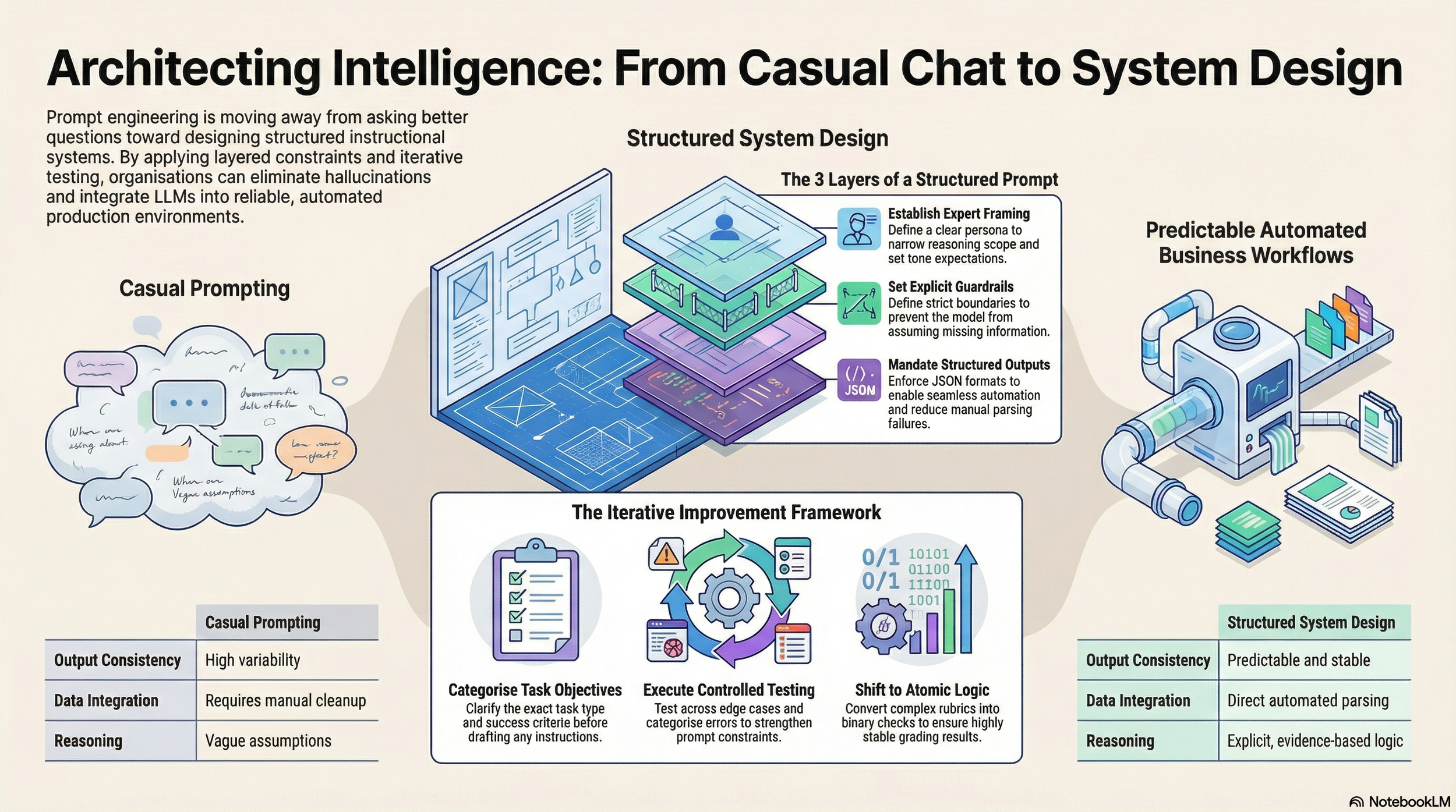
Step 1: Define the Objective Before Writing
Before drafting a prompt, we first clarify the objective to prevent ambiguity and unnecessary complexity. We ask ourselves:
What is the exact task type? (Classification, extraction, evaluation, generation, etc.)
What does a successful output look like?
Does the output need to be structured?
Instead of writing a vague instruction like:
"Analyze this text."
We define:
What kind of analysis? Based on what criteria? In what format should the answer be returned? What constraints should the model follow?
The clearer the objective, the simpler and more effective the prompt becomes. When the objective is unclear, the model fills the gaps on its own—and that often leads to inconsistent results.
Step 2: Structuring the Prompt in Layers
Over time, we developed a layered structure for writing prompts. This helps maintain clarity and consistency across our systems.
1. Role Definition We assign the model a clear role. For example: "You are a domain expert performing structured evaluation." Role framing narrows the reasoning scope and sets expectations for tone and decision logic.
2. Clear Task Instructions Instead of vague instructions like "Review this content," we clearly specify exactly what to evaluate, what criteria to follow, what to identify, and what to ignore. If the task is complex, we break it into smaller steps. Step-by-step instructions reduce confusion and improve output quality.
3. Constraints and Guardrails Constraints are critical in prompt design. Without guardrails, models often over-explain, assume missing information, add extra commentary, or ignore formatting rules. We explicitly define boundaries such as:
Do not assume information that is not present.
If data is missing, respond with "insufficient information."
Do not provide explanations outside the requested format.
Follow instructions strictly.
One important lesson we learned: Models perform better when boundaries are explicit.
4. Structured Output Format One of the biggest improvements in our prompt engineering journey was shifting from open-ended responses to structured outputs. Free-text responses broke downstream parsing, required manual cleanup, and caused evaluation gaps.
To solve this, we enforced strict structured outputs (for example, JSON with predefined fields). This ensured consistency, enabled automation, and reduced manual intervention. Structured output brings structured behavior.
Real-World Implementations
To see how this works in practice, here is how structured prompting transformed three of our automated workflows.
Case Study 1: AI-Assisted Candidate Evaluation
The system evaluated linguist profiles against structured job requirements (language pairs, domain experience, content type, certifications). The output directly influenced shortlisting decisions and fed into downstream systems, meaning it had to align strictly with business rules.
The Problem: Vague prompts allowed the model to infer skills not explicitly mentioned, assume language matches, and return free-text that caused integration issues.
The Fix: We redesigned the prompt to use only explicit evidence, distinguish mandatory vs. preferred requirements, avoid hallucination, and enforce strict JSON output.
The Impact: Reliable automated shortlisting, reduced manual validation effort, and eliminated parsing failures. The system moved from experimental outputs to controlled decision support.
Case Study 2: AI Translation QA & Review Workflow
The objective was to automatically evaluate and correct translations across standardized MQM dimensions (accuracy, fluency, terminology) without hallucinating changes.
The Problem: Error reporting was inconsistent, terminology validation lacked strict enforcement, and severity classification was subjective. Models also over-penalized stylistic variations.
The Fix: We separated terminology validation from general QA, enforced language-agnostic categories, restricted outputs to structured JSON, and introduced severity assessments based on business risk and user impact.
The Impact: Reduced inconsistency in QA reporting, enabled automated parsing of error data, improved terminology compliance, and significantly increased release confidence for translated content.
Case Study 3: Automated Candidate Grading
Structured prompting was implemented in evaluation workflows where LLMs graded candidate responses using predefined rubrics.
The Problem: YES/NO grading was inconsistent, and models assigned grades without citing evidence. The scoring logic inadvertently rewarded the presence of errors instead of quality.
The Fix: We converted rubric questions into atomic binary checks. We required a direct evidence quote (≤10 words) for every positive grade, reversed scoring logic to reward error-free quality, and moved formatting rules to system-level instructions.
The Impact: This redesign dramatically reduced false negatives and hallucinated justifications. The evaluation system became highly stable across repeated runs.
Our Prompt Improvement Framework
Prompt engineering is rarely perfect on the first attempt. Improvement requires structured iteration, testing, and analysis.
Baseline Creation: Design an initial structured prompt.
Controlled Testing: Test across typical cases, edge cases, and ambiguous inputs.
Error Categorization: Identify formatting issues, hallucinations, logic gaps, and inconsistencies.
Targeted Refinement: Strengthen constraints, simplify wording, and enforce structure.
Re-evaluation: Measure consistency and compliance improvements.
Prompt improvement is measurable. Consistency and reliability increase with iteration.
Final Thoughts: Techniques We Frequently Use
Clear role framing
Layered instruction design
Strict structured output schemas
Explicit edge-case handling
Step-by-step breakdown
Controlling verbosity
Reducing unnecessary complexity
More instructions do not always mean better results. Clear and structured instructions perform best.
👉 At Vaarta Analytics, we see AI implementation not as a one-off deliverable, but as a journey. Over the past year, structured prompt engineering has helped our clients move from scattered, unpredictable outputs to a unified, trusted AI ecosystem that scales with their business needs.
🧠 Visual Recap: Mind Map of This Article
A structured overview of everything we explored above — ideal for revisiting or sharing.
Why Teams Work with Vaarta Analytics
At Vaarta Analytics, we do not just provide analytics services. We act as a partner who builds what teams truly need.
From BI and Data Engineering to AI-powered systems and AI agents, our work is designed to remove bottlenecks, accelerate research, and
create space for innovation.
Whether you are an early-stage startup or a scaling enterprise, our tailored solutions help you:
Make smarter, faster decisions
Streamline complex workflows
Improve product launch readiness
Drive sustainable growth with data and automation