Reading Regulatory Filings with AI: An Internal Experiment
Regulatory filings are written for compliance, not for consumption.
Documents such as Draft Red Herring Prospectuses (DRHPs), Red Herring Prospectuses (RHPs), and final prospectuses are dense, repetitive, and often run into hundreds or even thousands of pages. Despite this, before any analysis can happen, a human still has to read and understand them.
While building internal tooling for a client, we repeatedly encountered this bottleneck. The challenge was not analysis or modeling. It was simply reading the source material efficiently and confidently. That observation led us to a separate internal experiment: could AI help people read long regulatory filings more effectively, without providing advice, opinions, or interpretations?
This post shares what we built and what we learned.
📽 Demo: Reading a DRHP with AI
Below is a short demo video showing how this internal experiment works in practice.
The video walks through:
Uploading a large regulatory filing (DRHP / RHP / final prospectus)
Background processing for high page-count documents
Generating factual summaries with page-level citations
Asking document-grounded questions and requesting plain-English explanations
Exporting standardized financial data into Excel with source references
Note: This demo reflects an internal experiment, not a public product.
The system is designed to help users read and understand regulatory filings. It does not provide investment advice, recommendations, or opinions.
▶ Watch the demo video:
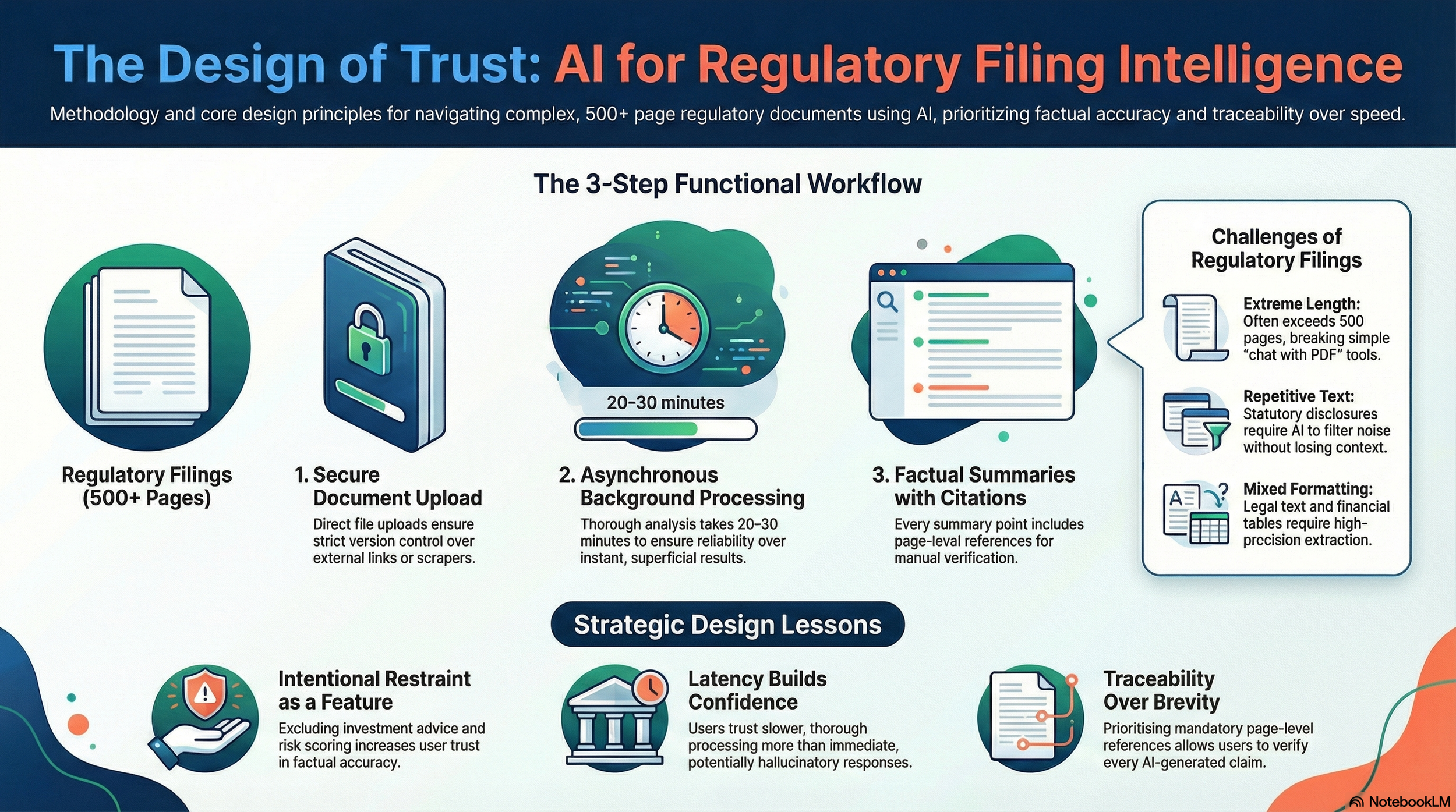
A deliberate constraint
From the start, we imposed a strict design constraint on this experiment.
The system should help users understand what a filing says, not tell them what to do.
That meant:
No investment advice
No recommendations
No scoring or judgments
No interpretation beyond what is explicitly disclosed
Even though this was an internal experiment, we wanted the system to behave realistically and responsibly. In regulated contexts, restraint is not a limitation. It is a requirement.
Why regulatory filings are uniquely hard to work with
Regulatory filings pose challenges that are very different from typical documents.
They are:
Extremely long, often exceeding 500 pages
Highly repetitive due to statutory disclosures
A mix of legal language, financial tables, and narrative text
Full of cross-references that require constant back-and-forth
Inconsistently formatted, sometimes with imperfect OCR
These characteristics make them difficult for both humans and automated systems. A simple “chat with PDF” approach often breaks down when documents are this large and structured. Any tool operating in this space has to prioritize reliability and traceability over speed.
How the experiment works
1. Document upload by design
Users upload a regulatory filing directly, such as a DRHP, RHP, or final prospectus.
We intentionally require file uploads rather than fetching documents via URLs. This ensures strict version control. By managing the file source directly, users know the system is analyzing the exact version they intend, without relying on external website availability, broken links, or scraper behavior.
This also avoids ambiguity when multiple versions of the same filing exist.
2. Background processing
Because filings can be several hundred pages long, processing runs asynchronously in the background.
For large documents, this typically takes 20 to 30 minutes. We deliberately chose not to optimize for instant answers. In a regulated context, users tend to trust slower, thorough processing more than immediate responses that may skip content or hallucinate details.
Being explicit about processing time also sets clear expectations and improves confidence in the system.
3. Factual summaries with traceability
Once processing is complete, the system generates a structured summary.
Each summary point:
Is derived directly from the document text
Includes page-level citations
Can be verified by the reader against the original filing
Nothing is inferred. Nothing is hidden. If information is not found, the system explicitly states that. This design prioritizes transparency over brevity.
4. Document-grounded Q&A and explanations
Users can ask questions about the filing and receive answers that are strictly grounded in the document text.
Every answer includes page references. If a question cannot be answered from the filing, the system says so clearly.
For particularly dense or legalistic passages, users can also request plain-English explanations. These explanations aim to clarify what the passage is saying, without adding interpretation, opinion, or advice.
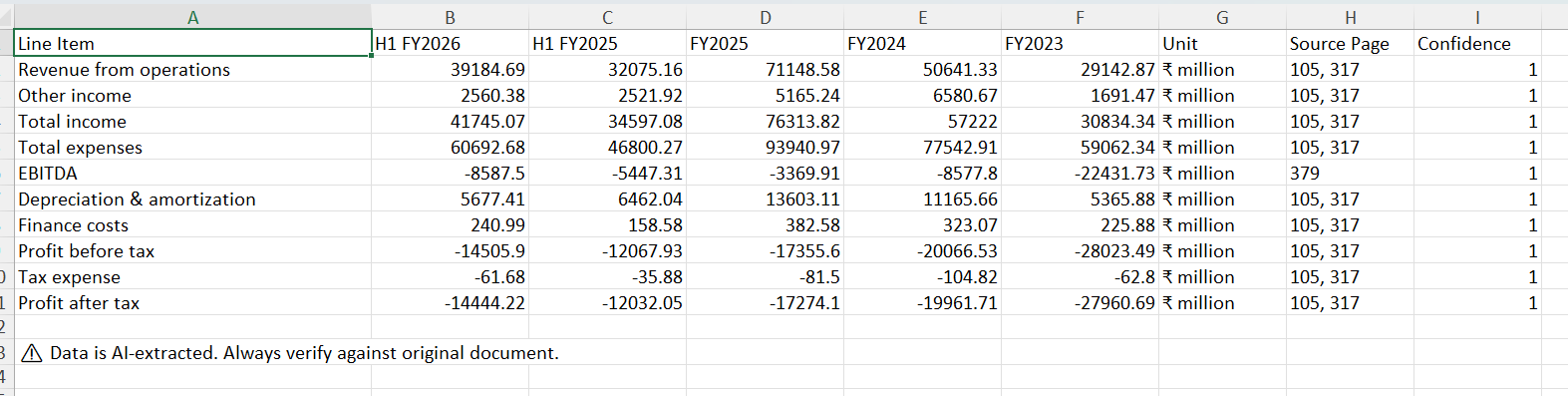
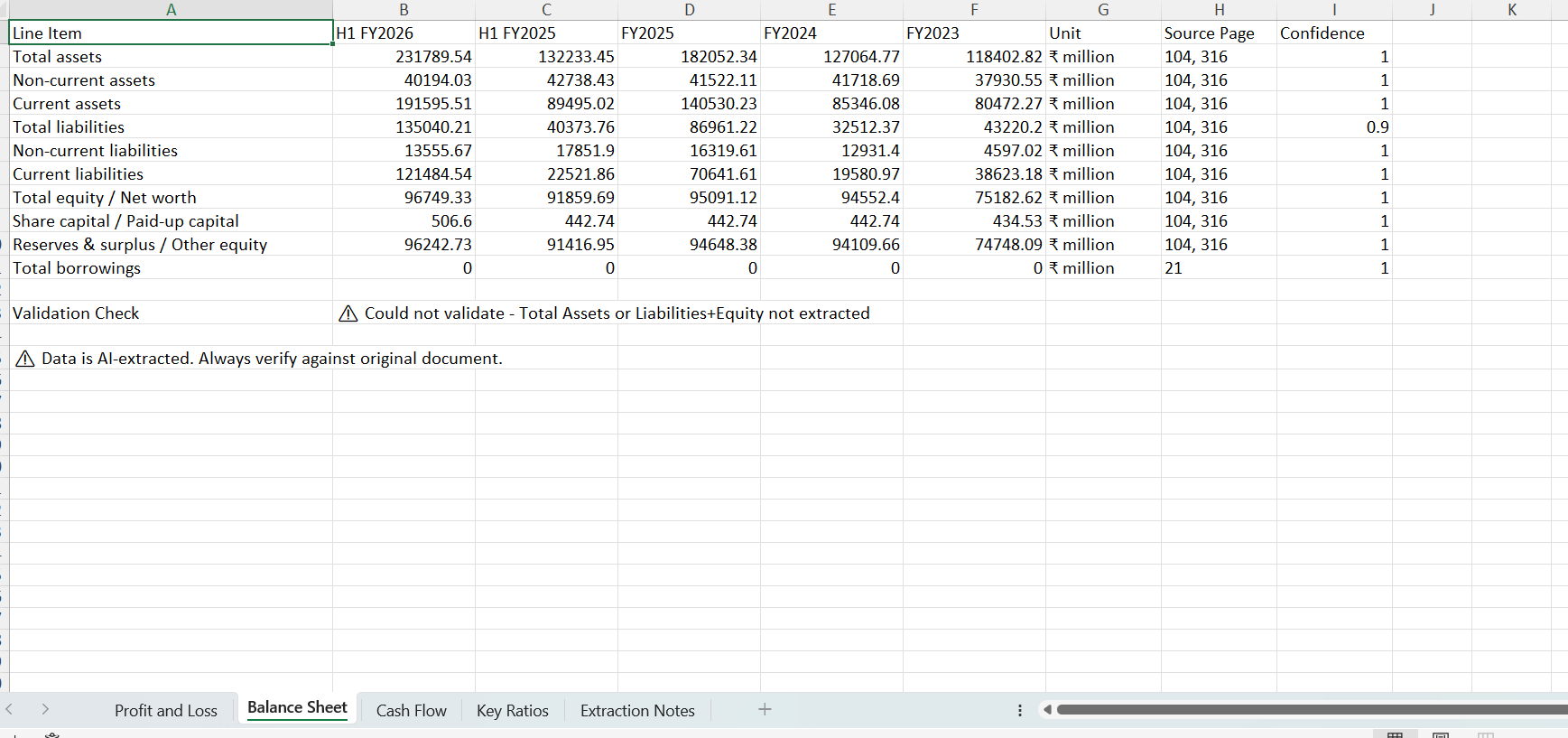
5. Downloadable financial data
The system can also export standardized financial data into Excel.
This includes:
Structured financial statements
Source page references for each data point
Transparency around extraction limitations
The goal is to reduce manual copy-paste from PDFs while keeping users aware that verification against the original document is still important.
Why we avoided a chat-first design
Many AI tools start with a chat interface. We intentionally did not.
For regulatory filings, starting with chat creates several problems:
Users cannot easily verify answers
Page-level traceability is often lost
The system may appear confident even when information is missing
Instead, we prioritized:
Structured summaries before Q&A
Mandatory citations
A reading-first workflow
This makes the system slower to impress, but easier to trust.
What we intentionally did not build
Just as important as what we built is what we chose not to build.
We avoided:
Investment guidance of any kind
Risk scoring or red-flag labels
Forensic or compliance verdicts
Predictive analysis
These features may be useful in other contexts, but they introduce regulatory and ethical complexity that was out of scope for this experiment.
What we learned
A few things became very clear during this experiment:
Friction is usually about workflow, not AI. The hardest problem was not summarizing text, but designing a way for users to verify outputs against the source document.
Latency can build trust. Users were often skeptical of instant answers on 500-page filings. Being upfront about processing time made the system feel more rigorous.
Restraint is a feature. Explicitly stating that the system does not give advice made users more comfortable using it for factual extraction and understanding.
Why we are sharing this
This is not a product launch.
It is a learning exercise that reflects how we approach building systems: start from real problems, move quickly, and define clear boundaries.
We are sharing this to document the thinking and design choices behind the experiment, not to sell a tool.
A short demo video is embedded for those interested in seeing it in action.
This experiment uses publicly available AI models and is intended for educational and exploratory purposes only.
🧠 Visual Recap: Mind Map of This Article
A structured overview of everything we explored above — ideal for revisiting or sharing.
Why Teams Work with Vaarta Analytics
At Vaarta Analytics, we do not just provide analytics services. We act as a partner who builds what teams truly need.
From BI and Data Engineering to AI-powered systems and AI agents, our work is designed to remove bottlenecks, accelerate research, and
create space for innovation.
Whether you are an early-stage startup or a scaling enterprise, our tailored solutions help you:
Make smarter, faster decisions
Streamline complex workflows
Improve product launch readiness
Drive sustainable growth with data and automation